Guys, there's been a huge stir in the AI community recently 😱! Google Gemini 3 made a splash late at night, proclaiming the crowning of a new king in the AI realm ✨.
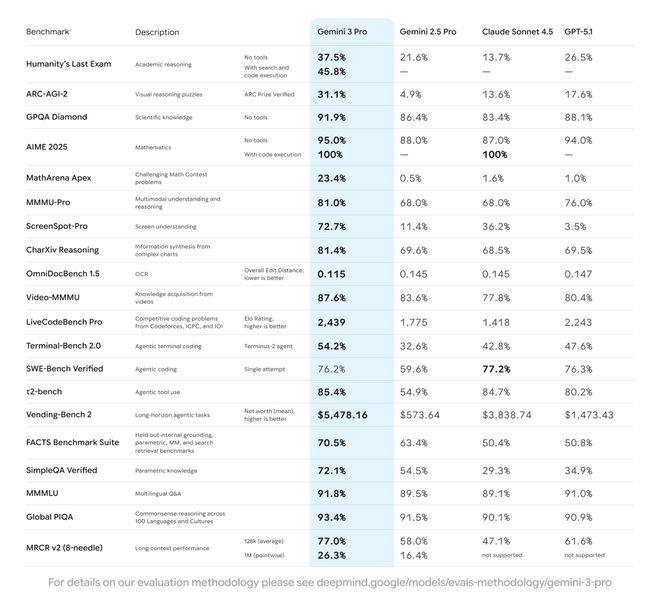
Previously, people were spoilt for choice among AI models, with the differences in advantages between various models being rather marginal. But as soon as Gemini 3 Pro arrived, its performance was simply outstanding 💯. In tests representing the "pinnacle" of human intelligence, it outscored GPT - 5.1 and Claude Sonnet 4.5 by a large margin. In mathematics, it shows absolute dominance. When combined with code execution in AIME 2025, its accuracy rate reaches 100%, and in MathArena Apex, it leaves other large - scale models far behind. Moreover, its "visual intelligence" is truly remarkable. Its understanding ability of screenshots is twice that of the current advanced level 👏.
Google also launched a "mini - bombshell", Google Antigravity. It's an agent - first development platform where developers can collaborate with multiple intelligent agents, skyrocketing their work efficiency 🚀. Additionally, Gemini 3 Pro is trained using Google TPU, with comprehensive data coverage. It has been integrated into Google Search, enabling it to instantly generate interactive charts or simulation tools when searching for complex concepts.
Online practical tests have also yielded good results, with its direct - generation ability proving to be quite powerful. Guys, the AI era is unstoppable. Let's start paying close attention right away 🤩!
Dear friends, there has been a major move in the AI field recently 🔥! Baidu has grandly released the new - generation multimodal AI model ERNIE - 4.5 - VL. In this era of rapid development of AI technology, it is really difficult to find an efficient and powerful AI model, which is the pain point of many developers and researchers 😭.
However, this time Baidu's new model perfectly solves these problems 👏. It not only has powerful language - processing capabilities but also introduces the innovative function of "image thinking". With only 3B activation parameters, it has extremely high computational efficiency and flexibility, and can handle tasks quickly and efficiently. Moreover, this "image thinking" function is extremely powerful. It can perform operations such as image zooming and tool - calling for image search, greatly enriching the interactive experience between images and text.
I think it will bring new possibilities to many fields such as intelligent search, online education, and e - commerce 💯. It's like equipping these fields with smart little wings, enabling them to fly higher and farther. Now this model is open - sourced, and developers and researchers can more conveniently explore the potential of multimodal AI. Dear friends, don't miss this great opportunity. Let's start researching together 👏!
#Baidu AI Model #ERNIE - 4.5 - VL #Multimodal AI #Image Thinking #AI Technological Innovation
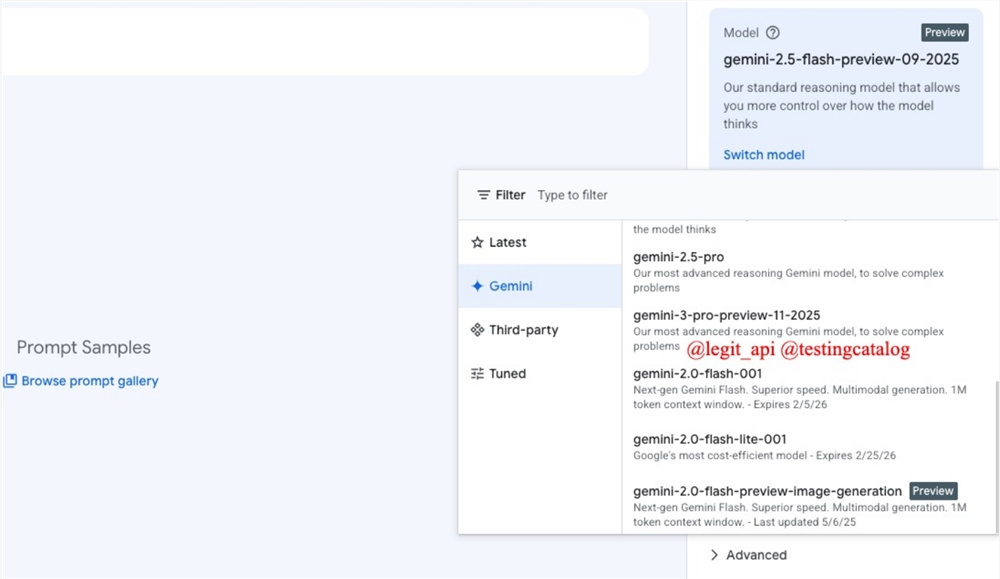
Dear friends, there's been a major development in the AI world recently 🔥! The Gemini series of artificial intelligence models under Google has made significant progress, and the latest preview version "gemini - 3 - pro - preview - 11 - 2025" has appeared on the Vertex AI platform.
Previously, many AI models struggled when dealing with long documents and complex tasks, which was really frustrating 😣. However, Gemini 3 Pro supports an extremely large context window of up to 1 million tokens, which is simply a savior 👍! It can handle 200,000 tokens at the standard level and directly extends to 1 million tokens at the advanced level. It has also been optimized in terms of input - output ratio and the proportion of image/video/audio processing.
It is regarded as a major upgrade of Gemini 2.5, focusing on multimodal reasoning and agent - based intelligence. The training data covers up to August 2024 and encompasses a variety of input sources. Industry analysts say that it is of revolutionary significance in the field of enterprise - level applications, such as financial modeling and biotech simulation.
According to reports from multiple tech media, Google may reveal more details in the middle to late November, and the full release may be postponed until December. Compared with its predecessors, it is expected to outperform GPT - 4o in benchmark tests and perform excellently in multimodal creative generation and code - writing tasks 👏. Although Google has not yet officially responded, Vertex AI is accelerating the iteration of the Gemini series. Let's all look forward to its official debut ✨!
Dear friends, OpenAI updated the usage policy of ChatGPT on October 29. This time, the model is clearly prohibited from providing professional medical, legal or financial advice!
This is mainly done to avoid regulatory risks, reduce the hidden danger of misleading people, and redefine the application boundaries of AI in high-risk fields. ChatGPT can no longer do things like interpreting medical images, assisting in diagnosis, drafting or interpreting legal contracts, providing personalized investment strategies or tax planning. If users raise such demands, the system will uniformly reply to guide them to consult human experts. Moreover, this policy covers all ChatGPT models and API interfaces to ensure consistent implementation.
Although professionals can still use it for general concept discussion or data organization, they cannot directly provide "fiduciary" advice to end users. This adjustment is driven by global regulation. The EU's Artificial Intelligence Act is about to take effect, which will conduct strict reviews on high-risk AI, and the US FDA requires clinical verification for diagnostic AI tools. By doing so, OpenAI can avoid being recognized as "software as a medical device" and also prevent potential lawsuits.
Regarding this new rule, users' reactions are divided into two camps. Some individual users feel quite regretful because they have lost the "low-cost consultation" channel. After all, they had saved a lot of professional consultation fees by relying on AI before. However, most of the medical and legal circles support it. After all, the "pseudo-professional" output of AI is indeed likely to lead to misdiagnosis or disputes. Data shows that over 40% of ChatGPT queries are of the advice type, and medical and financial advice account for nearly 30%. This policy may lead to a short-term decline in traffic.
It also has a significant impact on the industry. Google, Anthropic, etc. may also follow suit and impose restrictions. Vertical AI tools, such as certified legal/medical models, may become popular. Chinese companies like Baidu have already complied in advance. Under the situation of stricter domestic regulation, innovation has to be explored within the "sandbox" mechanism.
OpenAI emphasizes that the goal is to "balance innovation and safety". This update continues the Model Spec framework, and it is said that there will be further iterations in February 2025. The transformation of AI from an "omnipotent assistant" to a "limited assistant" seems to have become an industry consensus. In the future, technological breakthroughs and ethical constraints will develop together. I wonder what new balance the GPT-5 era will bring?
What do you think of this new rule of ChatGPT? Come and share your thoughts in the comment section!
Dear friends, there's extremely important news! Google is busy preparing to release the AI image generation model Nano Banana2, with the internal code name "GEMPIX2". Judging from the new announcements on the official Gemini website, it may meet us in the next few weeks!
The Nano Banana series is the ace of Google's DeepMind team. Since the first generation was launched on August 26, 2025, it has been extremely popular. It topped the LMArena image editing leaderboard during the early preview. Its "multi-round dialogue" interaction and character retention functions are excellent. It can easily blend photos, change backgrounds, and generate artistically styled images. In just a few weeks, it has attracted 10 million new users to join the Gemini ecosystem, with more than 200 million image editing operations!
Judging from the preview cards and technical indicators on the Gemini UI interface, the exposure of Nano Banana2 this time indicates that it will continue to focus on creativity, optimize the visual generation speed and artistic style diversity for professional creators and developers, and may also be deeply integrated with the Gemini3.0 series to enhance the multimodal processing ability, such as the generation of customized visual styles for video overviews.
Although Google has not announced the specific details yet, it feels like the release is just around the corner. Maybe it will appear together with the updates of products such as NotebookLM and Google Photos. The first-generation model has made the monthly active users of Gemini exceed 650 million. With the arrival of Nano Banana2 this time, it is expected to further narrow the gap with its competitors and inject new vitality into the creative industry. Moreover, Google emphasizes that all generated images will be marked with watermarks to ensure compliance.
What are your expectations for Nano Banana2? Come and chat in the comment section!
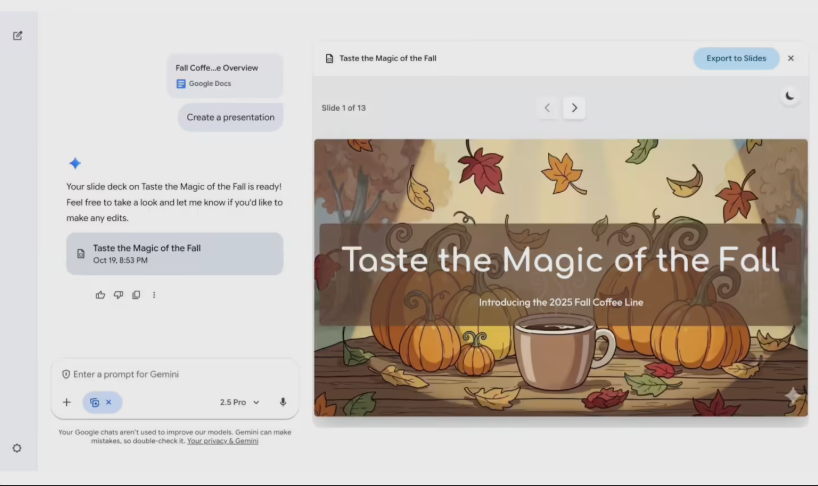
Guys, the era of tedious PPT making may really be coming to an end! Google has introduced a super useful new function for the AI assistant Gemini. In Geminis interactive workspace Canvas, you can automatically generate super professional PPTs just by entering a one-sentence prompt. It can be used by both individual users and Google Workspace accounts!
This function is super intelligent, "fast" and "accurate". If there is no specific material, for example, if you enter "Create a presentation on climate change", it can automatically organize the content framework, match the theme style and insert relevant pictures. If there are existing materials, just upload Word documents, PDF reports or Excel spreadsheets, and it can extract key information and transform it into clear and logical slide content.
Moreover, the generated PPTs are not static finished products. They can be directly exported to Google Slides. On this basis, you can freely adjust the layout, add or delete content, and collaborate in real time with team members. Its a proper efficient workflow of "AI drafting + manual optimization".
This is an important iteration of Google since the launch of the Canvas workspace in March this year. From initially supporting collaborative editing of text and code to now expanding to multimodal content generation, Gemini is striding forward towards a deep productivity tool!
Have any of you guys used this function? Come and share your experiences in the comment section!
Dear folks, ByteDance has once again made a remarkable move in the AI realm! Collaborating with research teams from multiple universities, it has integrated the advanced vision - language model LLaVA and the segmentation model SAM - 2, unveiling an amazing new model, Sa2VA! 🎉
LLaVA is an open - source vision - language model that excels in macroscopic video narration and content comprehension, yet it struggles a bit with detailed instructions. SAM - 2, on the contrary, is an outstanding image segmentation expert capable of identifying and segmenting objects within images, but it lacks language - understanding capabilities. To leverage their respective strengths, Sa2VA effectively combines these two models through a simple and efficient "code - word" system. 🧐
The architecture of Sa2VA resembles a dual - core processor. One core is tasked with language understanding and dialogue, while the other is responsible for video segmentation and tracking. When a user enters an instruction, Sa2VA generates a specific instruction token and passes it to SAM - 2 for concrete segmentation operations. In this manner, the two modules function in their areas of expertise and can also engage in effective feedback - based learning, constantly enhancing the overall performance. 😎
The research team has also designed a multi - task joint training curriculum for Sa2VA to boost its capabilities in image and video understanding. In numerous public tests, Sa2VA has demonstrated excellent performance, particularly shining in the video referential - expression segmentation task. It can accurately segment in complex real - world scenarios and can even track target objects in real - time within videos, boasting extremely strong dynamic - processing capabilities. 👏
Moreover, ByteDance has made various versions of Sa2VA and its training tools publicly available, encouraging developers to conduct research and applications. This provides abundant resources for researchers and developers in the AI field, propelling the development of multimodal AI technology.
Here are the project addresses:
https://lxtgh.github.io/project/sa2va/
https://github.com/bytedance/Sa2VA
Dear friends, are you looking forward to Sa2VA? Come and share your thoughts in the comment section! 🧐
#ByteDance #Sa2VA #Multimodal Intelligent Segmentation #LLaVA #SAM-2 #AI Model #Open-source
Guys, Google has made a big splash in the AI field again! Recently, it proposed the revolutionary framework "Reasoning Memory" (learnable reasoning memory), aiming to enable AI Agents to achieve true "self - evolution", which is simply stunning 👏.
First, let's talk about the pain points of current AI agents. Currently, AI Agents based on large language models perform well in reasoning and task execution, but they generally lack a sustainable learning mechanism. AIbase analysis shows that existing intelligent agents do not "grow" after completing tasks. Each execution is like starting anew, which brings a bunch of problems. For example, they make repeated mistakes, can't accumulate abstract experience, waste historical data, and have limited decision - making optimization. Even if a memory module is added, most of them are just simple information caches, lacking the ability to generalize, abstract, and reuse experience. It's very difficult to form "learnable reasoning memory", and thus they can't truly improve themselves 😔.
Next, look at Google's new framework. The Reasoning Memory framework is a memory system specifically designed for AI agents, which can accumulate, generalize, and reuse reasoning experiences. Its core is to enable agents to extract abstract knowledge from their own interactions, mistakes, and successes to form "reasoning memories". Specifically:
Experience Accumulation: Agents no longer discard task history, but systematically record the reasoning process and results.
Generalization and Abstraction: Use algorithms to turn specific experiences into general rules, not just simple episodic storage.
Reuse and Optimization: Call on these memories in future tasks, adjust decisions according to past experiences, and reduce repeated mistakes.
This mechanism allows AI agents to "learn from mistakes" like humans and achieve closed - loop self - evolution. Experiments show that agents equipped with this framework have a significantly improved performance in complex tasks. This is a huge leap from static execution to dynamic growth 😎.
Finally, let's talk about the potential impact. AIbase believes that this research can reshape the AI application ecosystem. In fields such as automated customer service, medical diagnosis, and game AI, Agents can continuously optimize their own strategies and reduce human intervention. In the long run, it fills the "evolution gap" of LLM agents and lays the foundation for building more reliable autonomous systems. However, there are also challenges. For example, the memory generalization ability and computational cost still need to be further verified. But anyway, Google's move has strengthened its leading position in the forefront of AI, which is worthy of attention from the industry 🤩.
Guys, what do you think of Google's new framework? Come and chat in the comments section 🧐.
Guys, the competition in artificial intelligence is getting fiercer. Google's Gemini 3.0 Pro model is about to debut, and it's really making waves👏.
Not long after the release of OpenAI's Sora2, the internal test version of Gemini 3.0 leaked online, and the actual test results shared by developers are extremely eye-catching, especially its excellent performance in programming🧐.
It is said that Gemini 3.0 will be officially launched next week. The internal test version has two models, Gemini 3.0 Pro and Gemini 3.0 Flash. Developers have found that Gemini 3.0 Pro has a very high accuracy rate in many programming tests. It performs amazingly in the face of complex code generation and physical simulation tasks😎.
For example, in the "hexagonal gravity friction of small balls" test, it can accurately simulate the movement of small balls, reasonably reflect the laws of physics, and easily handle acceleration rotation, size change, environmental resistance, etc. It's also great at generating SVG images, and can generate complex graphics like a "pelican riding a bicycle" with one click.
However, Gemini 3.0 Pro is not perfect. In the comparison test with Claude Sonnet4.5, it failed the six-finger hand vision test. And Gemini 3.0 Flash has also been praised by developers for its amazing speed and accuracy in solving specific problems such as travel planning.
Judging from the internal test performance of Gemini 3.0 Pro, it can be seen that Google has great strength in the programming field. Its official launch is imminent, which makes many developers full of anticipation. It feels like a new coding era is really coming, and maybe this AI tool of Google will lead the future development trend🤩.
Guys, what do you think of Gemini 3.0 Pro? Come and chat in the comments section🧐.
Hey guys, who gets this feeling? I just saw OpenAI’s new feature and was totally blown away! Sam Altman (y’know, ChatGPT’s big boss) is raving about it, calling it “my favorite feature so far.” How awesome could it be? Let’s dive in together and check it out!
✨The New Feature Is Called “ChatGPT Pulse”—It Totally Changes the Traditional Way We Use ChatGPT!
It works quietly while you sleep, and hands you ready-to-use, useful stuff first thing in the morning!Before, we had to take the initiative to ask ChatGPT questions; it’d only answer when we asked, like a “passive question-answering machine.” But now, Pulse has transformed into a “proactive little butler.” Its core trick?
Right now, it’s exclusive to Pro subscribers (paid users get to jump the queue), and it’ll roll out to Plus users later. Eventually, the goal is to make it available to everyone! This is definitely one of those “early adopters get the best experience” deals~
What Exactly Can It Do for You? Examples Make It Easier to Understand!
If you mention to it, “I want to travel to Bora Bora,” the next day it’ll send you local weather updates, off-the-beaten-path travel guides, and flight discounts—even the commute info you didn’t notice will be all sorted out for you!
Say “My baby is 6 months old,” and it’ll immediately send you baby development milestones + practical tips for new parents—way more in tune with your needs than a parenting blogger!
It can even connect to your calendar and email! It’ll help you draft meeting agendas, remind you to buy a birthday gift for your bestie, and recommend tasty, no-fail restaurants in the city you’re traveling to for work… Isn’t this basically the prototype of the real-life “Jarvis”?
💡My Favorite Part: No “Endless Scrolling”!
These days, apps do everything to keep you scrolling nonstop, but Pulse goes the opposite way! The tech lead straight-up said: “The experience has an end—it’s designed to serve you, not make you addicted.”
The content sent every day is carefully curated; once you finish reading, that’s it. Each piece is only valid for the day—no trapping you in an information vortex. This is so great for folks who love scrolling but hate wasting time!
⚠️But There’s a Small Concern: Can You Accept “Convenience in Exchange for Privacy”?
If you want Pulse to “understand you,” you have to give it some “permissions”:
It will access your past ChatGPT conversations (you need to turn on “Reference History” first).
To connect your calendar/email, you have to manually click “Accept” to give it access.
Even though OpenAI says “data processing is the same as regular conversations” and mentions “multiple security filters,” they haven’t shared details on how those filters actually work… It’s basically “black-box protection.” Whether you’re willing to trade personal data for convenience is something you guys have to weigh for yourselves~
🌟The Future Looks Promising: ChatGPT Is Shifting from “Question-Answering Machine” to “Action-Taker”!
The official team didn’t hold back: This is just the first step! Future ChatGPT will be even more powerful—it’ll automatically make plans for you, take action based on your goals, remind you at key moments, and even collaborate with you like a “team member”!
Imagine this: No more searching for travel guides, remembering schedules, or organizing information by yourself—AI will handle all that work for you… Traditional search engines and news apps are probably starting to sweat!
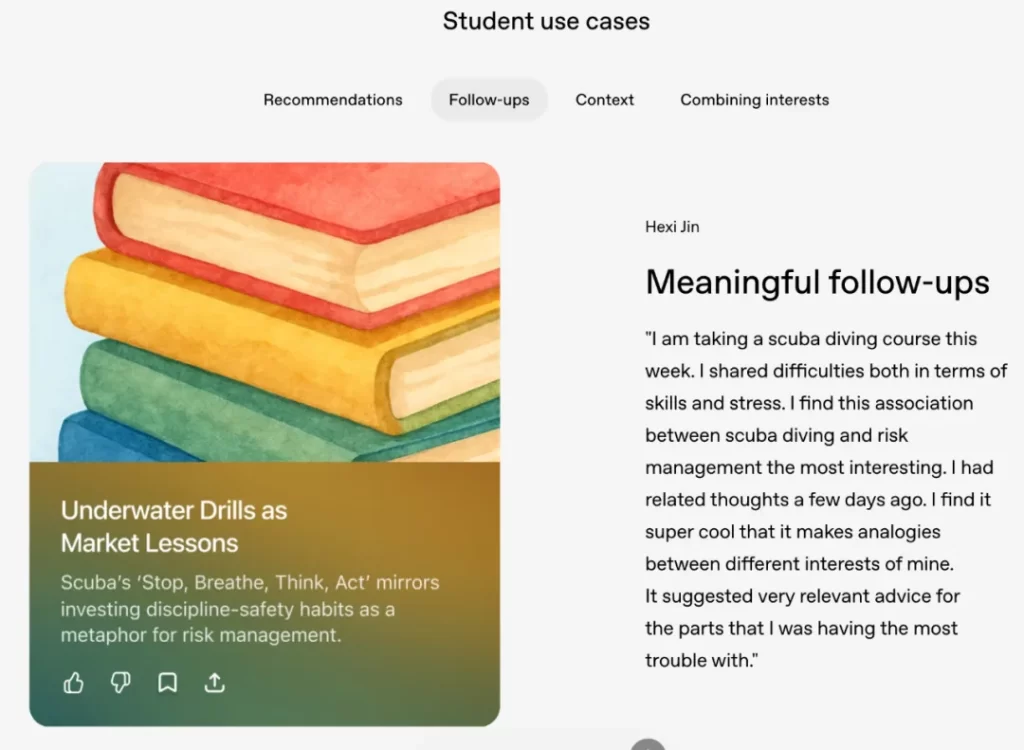
Right now, Pulse is still in its early version, but college students who tested it already say it’s a game-changer: At first, they thought it was just okay, but once they told it clearly what they wanted, they were shocked by its ability to “draw inferences from one example.” For instance, a scuba diving enthusiast mentioned having trouble during their diving training—Pulse not only gave advice but also made an analogy between scuba diving and risk management, hitting right on their interests!
What do you guys think of this new feature? Will you upgrade to Pro for it, or are you worried about privacy issues? Let’s chat in the comments!👇