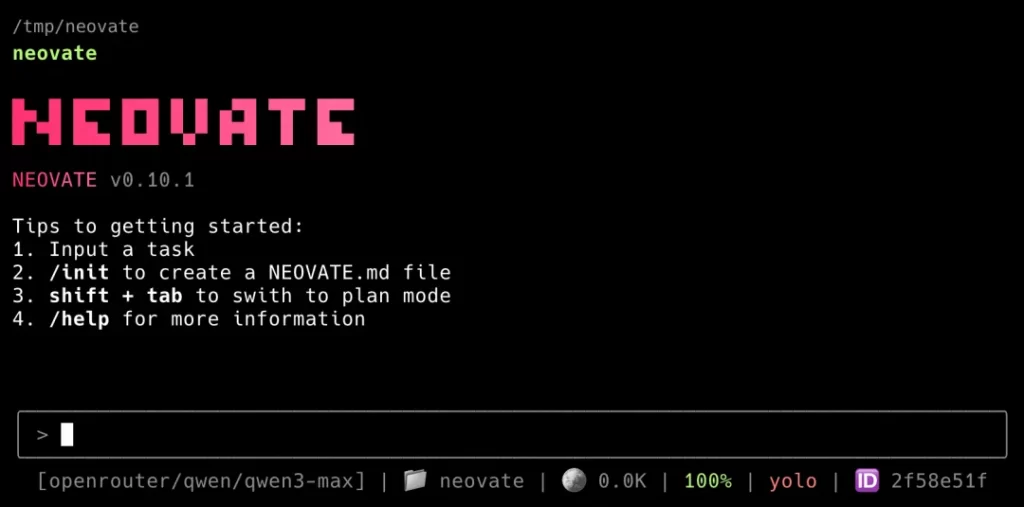
The Experience Technology Department of Alipay, Ant Group, has officially open-sourced the intelligent programming assistant Neovate Code. It can deeply understand your codebase, follow the existing coding habits, and accurately complete function implementation, bug fixing, and code refactoring based on context awareness. It integrates the core capabilities required by Code Agent. GitHub:https://github.com/neovateai/neovate-code
At present, Neovate Code is provided in the form of a CLI tool, but its architecture is highly flexible and will support multiple client forms in the future to adapt to more development scenarios.
Its main functions include: Conversational development - A natural dialogue interface for programming tasks AGENTS.md rule file - Define custom rules and behaviors for your project Conversation continuation and resumption - Continue previous work across conversations Support for popular models and providers - OpenAI, Anthropic, Google, etc. Slash commands - Quick commands for common operations Output style - Customize the way code changes are presented Planning mode - Review the implementation plan before execution Headless mode - Automate the workflow without interactive prompts Plugin system - Extend functionality with custom plugins MCP - Model context protocol for enhanced integration Git workflow - Intelligent commit message and branch management …
Dear friends, there's new news about DeepSeek! The latest model, DeepSeek-V3.1-Terminus, has made its debut! 👏
This version comes in two modes: the thinking model and the non-thinking mode, both with a context length of 128k. It is an upgrade based on DeepSeek-V3.1 and has two major improvements. First, in terms of language consistency, it alleviates the mixing of Chinese and English and the occurrence of occasional abnormal characters. For example, the "extreme" character issue mentioned before has also been improved. Second, in terms of Agent capabilities, the performance of Code Agent and Search Agent has been further optimized, making them even more outstanding. DeepSeek's last update was on August 21st. It's only been a month, and the new model DeepSeek-V3.1-Terminus has outperformed Gemini 2.5 Pro in many evaluations.
However, in terms of benchmark performance, compared to DeepSeek-V3.1, it has only a slight overall upgrade, and there is a slight decline in some benchmarks. But in the Humanity's Last Exam benchmark, the improvement is huge, as high as 36.48%, jumping from 15.9 to 21.7. That's really amazing!
Now, DeepSeek-V3.1-Terminus has been launched on apps, web pages, and APIs.
Here are two addresses for you: Hugging Face 地址: https://huggingface.co/deepseek-ai/DeepSeek-V3.1-Terminus
By the way, the word "Terminus" means "end". Does this imply that this is the last version of the V3 series and that DeepSeek - V4/R2 is coming soon? It's really exciting!
Dear friends, what do you think of DeepSeek-V3.1-Terminus? Come and share your thoughts in the comments section!
MobiAgent は本当にすごいです。誰もが自分だけの AI アシスタントを作る機会を得られます。このツールチェーンは、ユーザーがゼロからモバイルエージェントを構築できるようにしており、操作データの収集、モデルのトレーニング、そして携帯電話への展開まで、一連のプロセスを完了できます。そして、オープンソースです。ユーザーは独自のデータを取得し、モデルを学習させ、個人のデバイスでインテリジェントアシスタントを使うことができます。とても便利です🥰
Dear friends, here's some big news! At 00:00 on September 1, 2025, the "Measures for the Identification of Artificial Intelligence-Generated and Synthesized Content" jointly formulated by multiple government departments officially took effect! 🎉 This measure puts forward regulatory requirements such as the mandatory addition of explicit and implicit identifications. From now on, AI-generated text, images, audio, and video must all show their "digital ID cards"🧐
Before this, many platforms such as Tencent, Douyin, Kuaishou, and Bilibili had already introduced detailed rules. Take Douyin for example, it has launched an AI content identification function and an AI content metadata identification reading and writing function, which help creators add prompt identifications and also provide technical support for content traceability👏
Now the ecological chain of AI-generated content has entered a stage of standardized management. Artificial intelligence is developing extremely rapidly. In 2024, the scale of China's artificial intelligence industry exceeded 700 billion yuan and has maintained a high growth rate year after year. However, the popularization of technology has also brought new risks. For example, there are more and more cases of it being used to create false news and carry out online fraud.
The core of the policy of the "Measures for the Identification" is the requirement of dual identifications. Explicit identifications should be "visible at a glance" to ordinary users. For example, add text explanations at the beginning and end of an article, or add voice prompts or special icons in audio and video. Implicit identifications, on the other hand, are to embed "hidden information" in the file metadata, including various key information.
This measure is of great significance. Professor Ren Kui, one of the drafters, said that it is the first time to include generation service providers, content dissemination platforms, and end users in a unified governance framework, forming a system progression with other regulations and clarifying the boundaries of responsibility. It can promote the standardized development of the AIGC industry, reshape the public's trust in AIGC technology, and also enhance China's voice in the field of artificial intelligence security governance, providing a model for global content governance👍
Let's talk about the dual identification system again. Explicit identifications should be directly perceived by users. Texts should mark words such as "generated by artificial intelligence" in specific positions, and the font should be clear. Implicit identifications focus on technical traceability, embedding metadata inside the file, containing various key information. There are clear labeling requirements for different types of AI-generated content.
The "Measures for the Identification" also encourages the use of AI for original content creation. Moreover, it clarifies the obligations of different entities at the legal level. Service providers need to ensure that the content meets the identification requirements. Dissemination platforms need to verify implicit identifications and add significant prompt identifications. Application distribution platforms need to verify the identification functions of service providers.
However, the implementation of this measure also faces challenges. Users may delete explicit identifications or avoid implicit ones through transcoding, making it difficult to accurately identify the content posted by malicious users. Lawyers suggest that content publishing platforms should assume more responsibilities. Professor Ren Kui suggests from a technical perspective the development of secure content implicit identification technology.
All in all, identification is a crucial step in the governance of AI-generated content. But to truly avoid risks, it is also necessary to refine laws and regulations, establish industry self-discipline standards, strengthen law enforcement efforts, and enhance international cooperation. Cross-border AIGC law enforcement is also a challenge. In the future, it is necessary to promote the coordination of technical identifications and establish cross-border law enforcement mutual assistance mechanisms. Dear friends, what do you think about the mandatory "labeling" of AI-generated content? 🤔
#AI-generated content #Mandatory labeling #Content security governance #Dual identification system #Main body responsibility #Supervision challenges
On the evening of August 19th, DeepSeek officially announced that the online model version has been upgraded to V3.1. The most significant improvement is that the context length has been extended to 128K, which is equivalent to being able to process super-long texts of 100,000 to 130,000 Chinese characters, suitable for long document analysis, code library understanding and multi-round dialogue scenarios.
Users can now experience the new version through the official website, App or WeChat mini-program. The API interface call method remains unchanged, and developers can switch seamlessly without additional adjustments.
This upgrade is not a major version iteration, but an optimization of the V3 model. Tests show that V3.1 has a 43% improvement in multi-step reasoning tasks compared to the previous generation, especially more accurate in complex tasks such as mathematical calculations, code generation and scientific analysis. Meanwhile, the situation of the model's "hallucination" (generating false information) has decreased by 38%, and the output reliability has been significantly enhanced. In addition, V3.1 has also optimized multilingual support, especially improving the processing ability of Asian languages and less common languages.
Although V3.1 brings important improvements, the release time of the next-generation large model DeepSeek - R2, which users are more looking forward to, is still uncertain. Previously, there was market speculation that R2 would be released from August 15th to 30th, but insiders close to DeepSeek said that this news is not true and the official has no specific release plan at present.
DeepSeek's update rhythm indicates that the V4 model may be launched before the release of R2. However, the official has always been low-key, emphasizing that "it will be released when it's done" and has not responded to any market speculation.
Recently, the news of the release of DeepSeek's next-generation large model DeepSeek - R2 has attracted widespread attention in the market. There is a rumor that DeepSeek - R2 will be released between August 15th and 30th. However, according to Tencent Technology, sources close to DeepSeek have confirmed to the media that this news is not true and DeepSeek - R2 has no release plan this month.
As early as the beginning of this year, news about the R2 model had already started to spread. At that time, it was predicted that the R2 model would be released on March 17th, but this claim was also denied by the official. So far, DeepSeek has not officially announced the specific release time and technical details of the R2 model, which has disappointed many observers.
According to reports, the DeepSeek team stepped up the development of the R2 model in June this year. Insiders revealed that CEO Liang Wenfeng is still not satisfied with the capabilities of the model, and the team is still improving its performance and is not ready for official use. Early news said that DeepSeek originally planned to launch the R2 model in May, but due to various reasons, the plan was delayed. The new model is expected to be able to generate higher quality code and have the ability to reason in non-English languages.
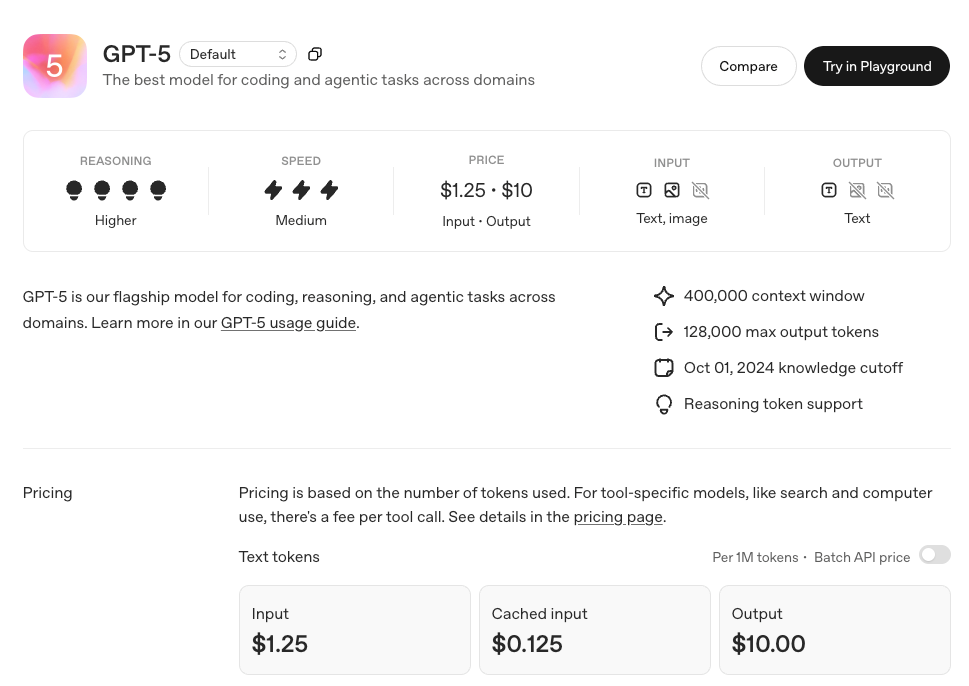
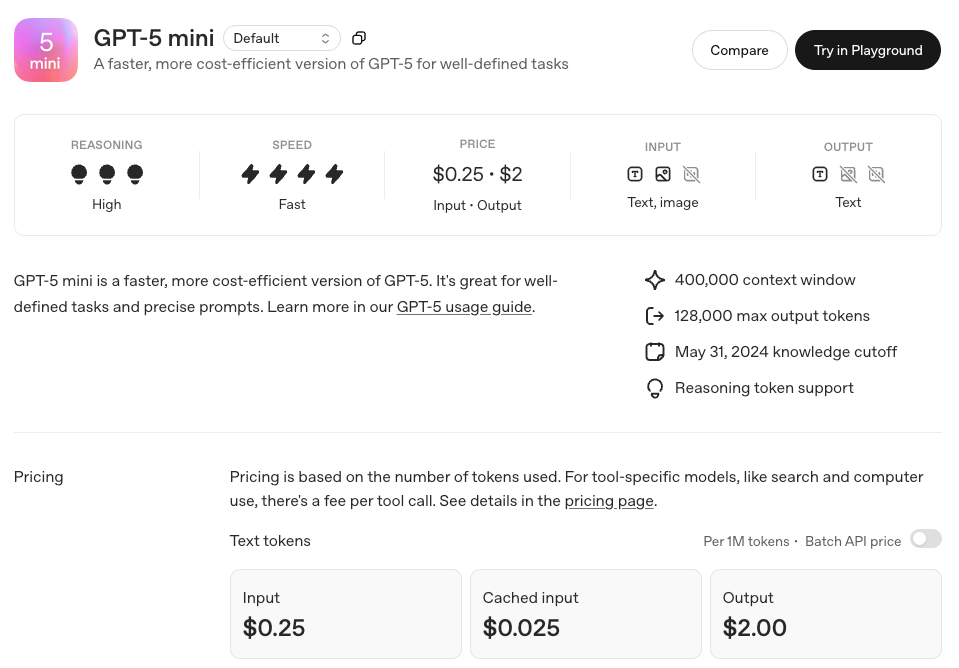
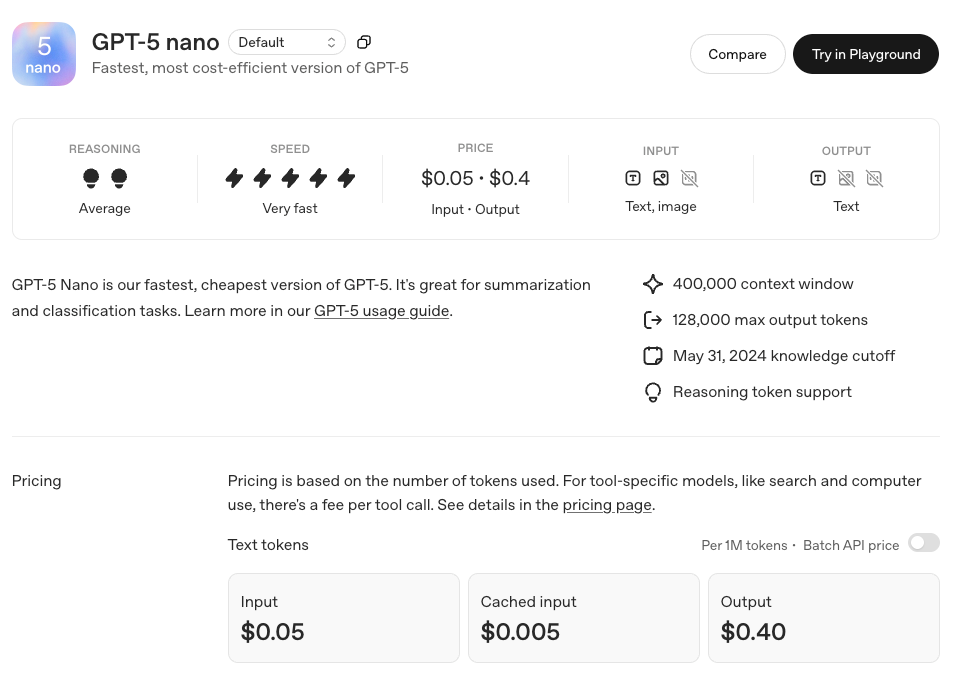
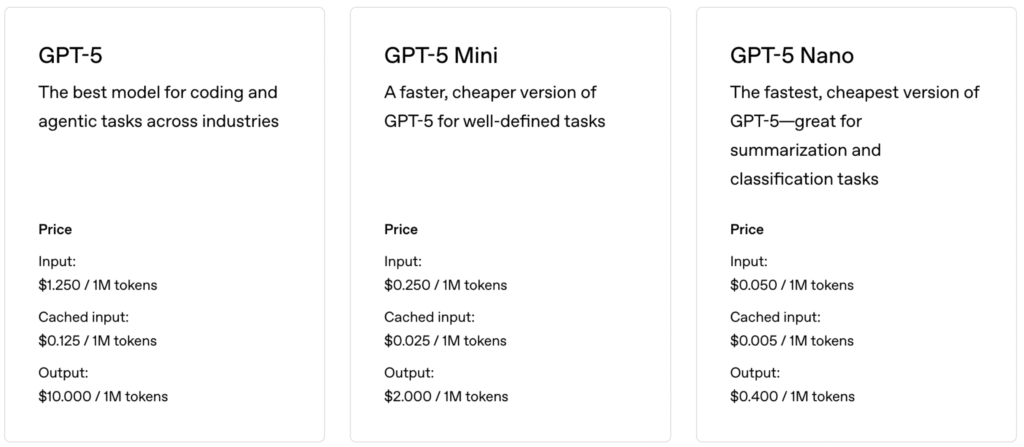
On August 7, 2025, OpenAI officially released the GPT-5 series of models, which represents the most significant product upgrade in the company's history. This release includes four versions: GPT-5, GPT-5 Mini, GPT-5 Nano, and GPT-5 Pro, each deeply optimized for different application scenarios, marking a new stage of development for AI technology.
Unified Intelligent System: A Revolutionary Breakthrough in Technical Architecture GPT-5 is positioned by OpenAI as a "unified intelligent system", successfully integrating capabilities that were previously scattered across different models: the multimodal processing of GPT-4o, the deep reasoning of the o series, advanced mathematical calculation, and agent task execution. This architectural innovation eliminates the need for users to manually switch between different models. The system automatically selects the most suitable processing method based on task complexity through a real-time router.
In terms of core technical indicators, GPT-5 has achieved a comprehensive breakthrough:
Mathematical Reasoning: Achieved an accuracy rate of 94.6% in the AIME 2025 benchmark test without the need for external tools. Code Capability: Scored 74.9% in the SWE-bench Verified test and 88% in the Aider Polyglot multilingual programming test. Multimodal Understanding: Scored 84.2% in the MMMU benchmark test. Professional Knowledge: Scored 88.4% in the GPQA general question answering test. Detailed Analysis of the Four Versions
未来规划也超值得期待😆,小米已经在对该模型进行计算效率的进一步升级,目标是在终端设备上实现离线部署。这意味着用户能在不依赖云端服务的情况下享受高质量音频 AI 服务,隐私保护更好,使用成本更低,还能为小米在 IoT 生态里的音频 AI 应用提供技术支持。另外,小米还在完善基于用户自然语言提示的声音编辑功能,以后通过简单文字描述就能完成复杂音频处理任务,音频编辑技术门槛大大降低啦🤩
小米选择全量开源 MiDashengLM-7B,真的超有意义👏。这能推动整个音频 AI 领域的技术进步,给研究者和开发者提供学习改进的好机会。开源能加速音频 AI 技术的普及应用,让更多创新应用出现,推动行业生态繁荣发展🎉
宝子们,感觉音频 AI 的新时代要来了,你们对这个 MiDashengLM-7B 怎么看呀🧐,快来评论区聊聊😜
#小米 #MiDashengLM7B #音频 AI #开源模型 #多模态大模型 #音频理解 #技术突破 #推理效率