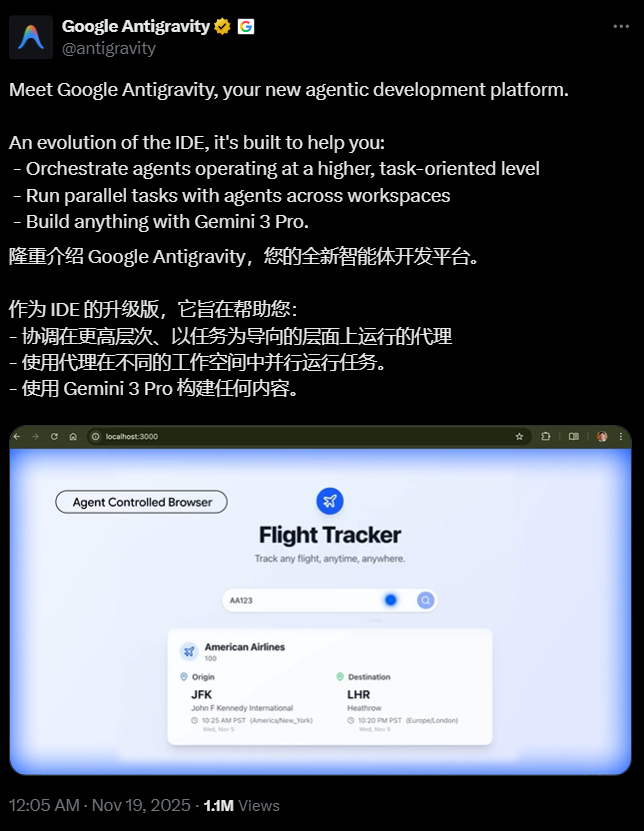
Dear friends, there's big news in the AI community today! 🔥Claude Opus4.5 might be officially launched today!
Previously, a new model entry with the code name "Claude Kayak" briefly appeared on the AI benchmark platform Epoch AI, marked with today's release date. Although it was quickly removed, it still attracted high attention from the global AI community. 🤩The industry generally believes that "Claude Kayak" is the flagship model Claude Opus4.5 that Anthropic is about to launch.

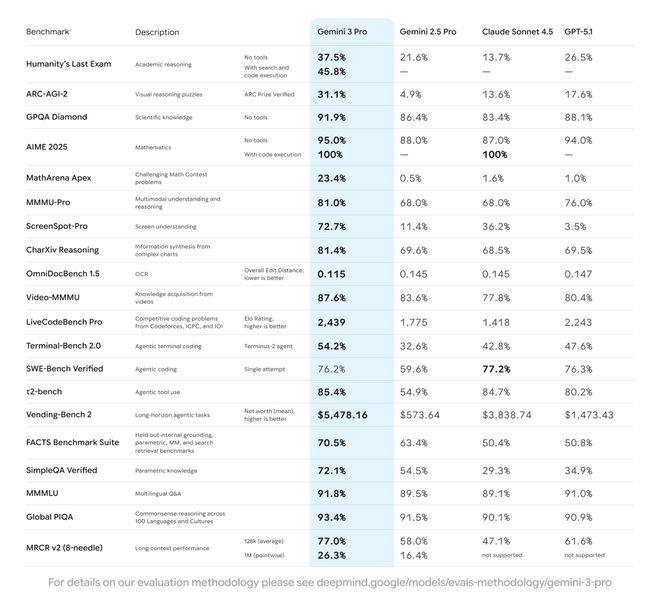
As a super - strong version of the Claude4 series, Opus4.5 is expected to significantly improve in complex reasoning, multi - step agent tasks, and code - generation capabilities. It is hoped to break the 80% score in authoritative evaluations, directly competing with OpenAI GPT - 5.1 and Google Gemini3.0Pro. 👏
Since the release of Opus4.1 in August this year, Anthropic has successively launched Sonnet4.5 and Haiku4.5. If Opus4.5 makes its debut as scheduled this time, the entire Claude4 series will be updated, and its position in the fields of multimodality and enterprise - level AI will be more solid. 👍
Now, developers are not only looking forward to the new model bringing stronger agent - coordination capabilities and longer context - handling capabilities but also worried that the high computing power requirements will make it "in limited supply" like the Opus series. Let's all wait for the official news. If it's really released, this will definitely be a major event in the AI competition at the end of 2025!
#ClaudeOpus4.5 #AI Release #GPT - 5.1 #GeminiPro #AI Competition