2026年4月24日,全球AI圈几乎被一件事刷屏了——OpenAI和DeepSeek在同一天发布了各自的旗舰模型。

这不是简单的版本迭代,而是两种截然不同的路线之争:一个向上堆算力、一个向下压成本,在通往AGI的道路上各走各的路,也对开发者发出了完全不同的信号。
今天这篇文章专门跟大家一起聊聊这个话题,希望对你会有所帮助。
一、向下压成本 vs 向上堆算力
评估一款大模型,我第一个要看的就是它的架构设计,这直接决定了它在真实负载下的表现。
DeepSeek V4:结构性的成本革命
DeepSeek V4的核心突破在于解决了超长上下文大模型在推理阶段的效率瓶颈。
其CSA与HCA混合注意力架构,本质上是一次对Transformer计算模式的底层重构。
传统Transformer中,注意力机制的计算量随序列长度呈平方级增长——序列翻倍,算力变四倍,这是决定性的瓶颈。
DeepSeek的混合注意力架构从根本上破解了这一难题:
- CSA压缩稀疏注意力解决的是“算什么”。它用轻量级索引器先对所有token对做粗筛,快速估算相关性排序,再精选出需要完整计算的token集合。关键在于——这套稀疏结构是可训练的,模型会自己学出哪里需要高密度注意力,哪里可以稀疏。
- HCA重度压缩注意力解决的是“存什么”。在DeepSeek V3时代MLA的基础上继续推进,将KV向量映射到低维潜空间,推理时解压。叠上FP4+FP8混合精度,KV缓存的显存占用再砍一半。
这套架构的成效可以用两个关键数字衡量:在百万token上下文设定下,V4-Pro的单token推理浮点运算次数仅为前代V3.2的27%,KV Cache内存占用更降至10%The
换算过来,同等算力下能服务的长上下文并发量大约是原来的3到4倍The
此外还有mHC流形约束超连接替代传统残差连接以增强深层网络信号传播稳定性,以及Muon优化器替代Adam系列。
基于矩阵正交化更新,在超大规模训练里收敛更快更稳定——Adam在大模型训练里几乎是默认配置近十年,DeepSeek这次把它换掉了,这是工程上的重要信号。
GPT-5.5:极致性能的“效能优化”
OpenAI在GPT-5.5上则展示了另一种路线。
它同样实现了百万级token上下文。
其核心能力之一是Token效率的突破The
完成同等任务使用的Token数量大幅减少,这与其混合专家架构和精细化的指令遵循能力直接相关。
在SWE-bench Verified基准测试中,GPT-4.1系列完成率即达到54.6%,较GPT-4o提升21.4个百分点。
在Terminal-Bench 2.0上,GPT-5.5达到了82.7%,领先Opus 4.7十三个百分点以上。
需要指出的是,GPT-5.5目前尚未公开详细的技术架构细节,这些基准测试数据是外界评估其能力的重要参照。
这一轮架构差异的本质:DeepSeek V4选择了一条结构性降本的路径——你算力少、显存小,也能用。
GPT-5.5选择了一条效能驱动的路径——Token用得更省,复杂任务执行得更准。
二、推理成本:制约业务规模的“天花板”
2026年4月24日,OpenAI与DeepSeek几乎同时发布了各自的新模型,两者的定价逻辑形成了鲜明对比。
| 模型版本 | 输入价格(每百万Token) | 激活参数量 | 核心定位 |
|---|---|---|---|
| GPT-5.5 Pro | $30.00 / 约218元 | – | 面向无限制、最高强度的高端企业级任务 |
| GPT-5.5 | $5.00 / 约36元 | – | 面向一般企业级的旗舰任务 |
| DeepSeek V4-Pro | 12元 | 490亿 | 对标顶级闭源模型的旗舰,适合最复杂任务 |
| DeepSeek V4-Flash | 1元(缓存命中0.2元) | 130亿 | 主打极速响应与极致性价比 |
这不仅是价格的差距,更多是背后战略的差异。
OpenAI的高定价,构建的是一个高端智能服务的护城河;
DeepSeek的低定价,则在铺设一条AI民主化的道路。
DeepSeek在百万token场景上的效率优化极为显著——V4-Pro单token推理算力为V3.2的27%,KV缓存仅10%;V4-Flash对应指标分别降至**10%和7%**。
这种效率提升直接体现在终端价格上。
对初创团队和中小型企业而言,DeepSeek的价格体系无疑是极大的利好。
三、开源护城河 vs 商业生态圈
DeepSeek V4:深植开源社区,构建开发者生态
- 完全开源:采用MIT协议,个人和企业均可免费下载权重并商用,显著降低了技术门槛。
- Agent生态优化:官方明确针对主流AI代理工具进行了专项适配和优化,对开发者非常友好。
GPT-5.5:强力构建商业闭环
- Codex生态:官方称85%的内部员工每周使用Codex,其目标是将自身建设为连接第三方工具和Agent的核心枢纽。
- 全栈服务能力:结合云端沙箱、Codex Agent等多重能力,为企业提供一站式解决方案。
两者各有侧重。
如果希望完全掌控模型并实现私有化部署,DeepSeek V4是明确的选择。
但如果追求极致的性能上限和完备的官方工具链,GPT-5.5依然是难以绕过的标杆。
四、总结
回到最初的问题:GPT-5.5和DeepSeek V4,哪个更好?
下面这张路线图可以帮助你根据自己的实际情况,做出最适合自己的选择:
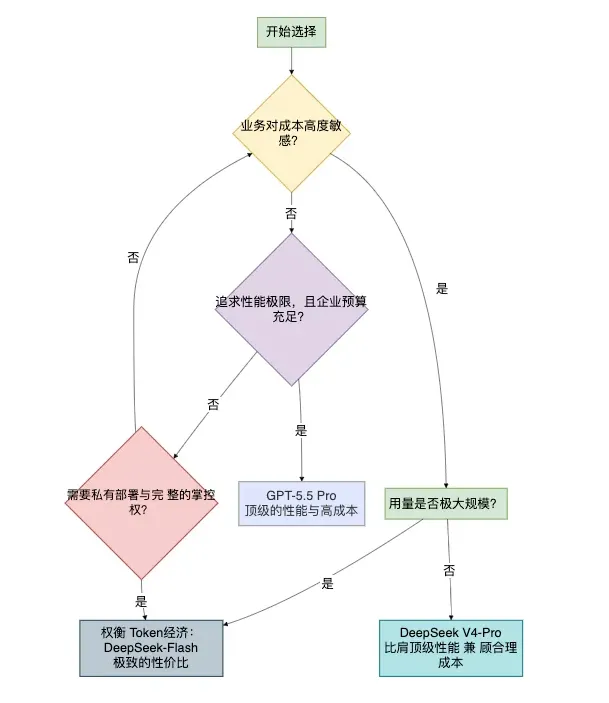
| 业务场景 | 推荐方案 | 核心理由 |
|---|---|---|
| 攻克业界难题、极限技术研究 | ✅ GPT-5.5 Pro | 追求性能上限,不考虑成本,适合需要最强模型托底的突破性项目。 |
| 企业级生产系统,追求性价比 | ✅ DeepSeek V4-Pro | 性能接近顶级闭源模型,但推理成本和KV缓存占用大幅降低。 |
| 个人开发者/初创团队,大规模调用 | ✅ DeepSeek V4-Flash | 极致性价比,输出价仅为GPT-5.5 Pro的1.55‰,适合对成本和弹性要求高的场景。 |
| 数据高度敏感,要求完全合规 | ✅ DeepSeek V4系列 | 完全开源,支持私有化部署且适配华为昇腾芯片,可控性高。 |
| 政企级高复杂度Agent任务 | ✅ GPT-5.5或V4-Pro | 两者作为当前SOTA,在复杂任务上有最佳表现,需根据成本权衡。对国产化有要求的场景优先V4-Pro。 |
在这场席卷全球的AI竞赛中,没有绝对的“优”,只有相对的“适”。