
新的音频模型快照以及生产语音应用程序对自定义语音更广泛的访问权限。
人工智能音频功能开启了用户体验令人兴奋的新领域。今年早些时候,我们发布了几款新的音频模型,包括 gpt – realtime,以及新的 API 功能,使开发人员能够打造这些体验。
上周,我们发布了新的音频模型快照,旨在通过提高整个生产语音工作流程(从转录、文本转语音到实时、原生语音转语音智能体)的可靠性和质量,应对构建可靠音频智能体时的一些常见挑战。
这些更新包括:
gpt-4o-mini-transcribe-2025-12-15用于通过转录或实时 API 进行语音转文本gpt-4o-mini-tts-2025-12-15用于通过语音 API 进行文本转语音gpt-realtime-mini-2025-12-15用于通过实时 API 进行原生、实时语音转语音gpt-audio-mini-2025-12-15用于通过聊天完成 API 进行原生语音转语音
新快照有一些共同的改进:
音频输入方面:
- 对于现实世界中的嘈杂音频,降低单词错误率。
- 在静音或有背景噪音时,减少幻觉情况(即生成无意义内容)。
音频输出方面:
- 语音输出更自然、更稳定,使用自定义语音时也是如此
价格与之前的模型快照保持一致,因此我们建议切换到这些新快照,以相同价格享受性能提升。
如果您正在构建语音智能体、客户支持系统或品牌语音体验,这些更新将帮助您使生产部署更加可靠。下面,我们将详细介绍新内容以及这些改进在现实世界语音工作流程中的体现。
语音转语音
我们正在部署新的实时迷你版和音频迷你版模型,这些模型针对更好的工具调用和指令执行进行了优化。这些模型缩小了迷你版和全尺寸模型之间的智能差距,使一些应用程序能够通过转向迷你版模型来优化成本。
gpt-realtime-mini-2025-12-15
gpt-realtime-mini 模型旨在与实时 API 配合使用,该 API 用于实现低延迟、原生多模态交互。它支持诸如音频流式输入输出、处理中断(可选语音活动检测),以及在模型持续对话时在后台进行函数调用等功能。
新的实时迷你版快照更适用于实时智能体,在指令执行和工具调用方面有显著提升。在我们内部的语音转语音评估中,与之前的快照相比,指令执行准确率提高了 18.6 个百分点,工具调用准确率提高了 12.9 个百分点,并且在 Big Bench 音频基准测试中也有所进步。
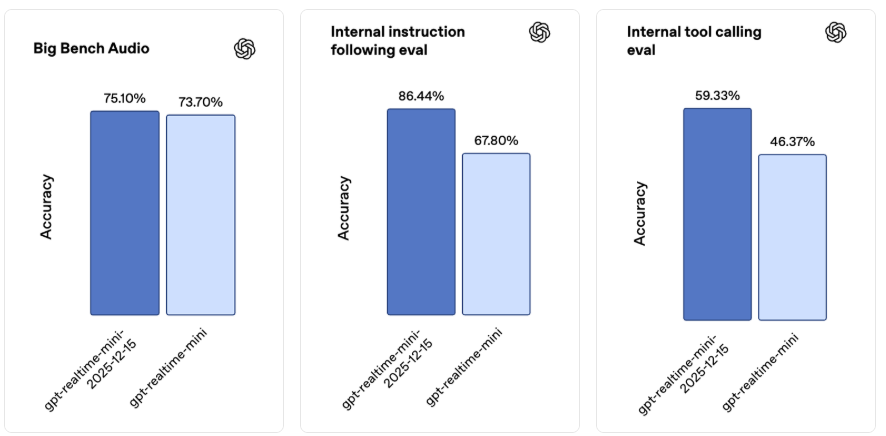
这些提升共同促成了在实时、低延迟环境中更可靠的多步骤交互以及更稳定的功能执行。
对于那些认为智能体准确性值得付出更高成本的场景,gpt – realtime 仍然是性能最佳的模型。但当成本和延迟最为关键时,gpt – realtime – mini 是个很好的选择,它在实际场景中表现出色。
例如,Genspark 在双语翻译和智能意图路由方面对其进行了压力测试,除了语音质量有所提升外,他们发现延迟几乎可以忽略不计,并且在快速交流过程中意图识别始终精准无误。
gpt-audio-mini-2025-12-15
gpt- audio-mini 模型可与聊天完成 API 配合使用,适用于那些对实时交互没有要求的语音转语音用例。
这两款新的模型快照还配备了升级的解码器,能让语音听起来更自然,并且在搭配自定义语音使用时,能更好地保持语音的一致性。
Text-to-speech
最新的转录模型 gpt-4o-mini-transcribe -2025-12-15 在准确性和可靠性方面都有显著提升。在诸如通用语音(Common Voice)和 FLEURS(无语言提示)等标准自动语音识别(ASR)基准测试中,它的单词错误率低于先前的模型。我们针对现实世界的对话场景对该模型进行了优化,例如适应简短的用户话语和嘈杂的背景环境。在一项内部带噪幻觉评估中,我们播放现实世界的背景噪音片段以及不同讲话间隔(包括静音)的音频,与 Whisper v2 相比,该模型产生的幻觉减少了约 90%,与之前的 GPT – 4o – transcribe 模型相比减少了约 70% 。
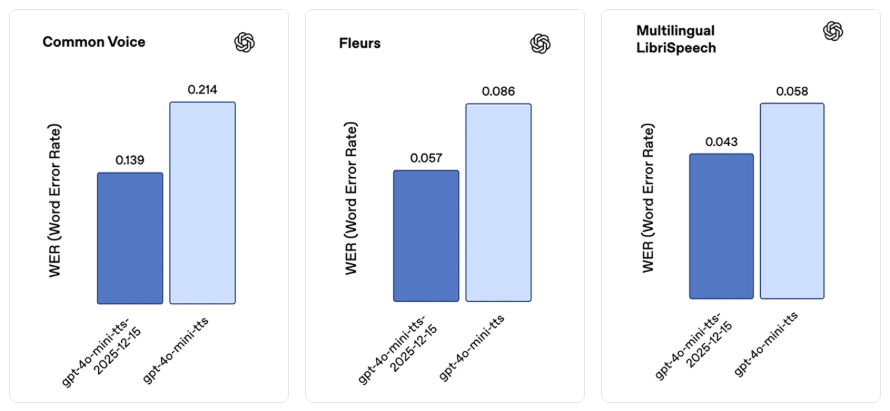
这些结果共同反映出该模型在多种语言中的发音准确性和稳定性都有所提高。
与新的gpt-realtime-mini快照类似,该模型的语音听起来自然得多,并且在搭配自定义语音使用时表现更佳。
Speech-to-text
最新的转录模型gpt – 4o – mini – transcribe – 2025 – 12 – 15在准确性和可靠性方面均有显著提升。在诸如通用语音(Common Voice)和FLEURS(无语言提示)这类标准自动语音识别(ASR)基准测试中,它的单词错误率比之前的模型更低。我们针对现实世界的对话场景对该模型进行了优化,比如应对用户简短发言和嘈杂背景等情况。在一项内部的带噪音幻觉评估中,我们播放包含现实世界背景噪音以及不同说话间隔(包括静音)的音频片段,与Whisper v2相比,该模型产生的幻觉减少了约90%,与之前的GPT – 4o – transcribe模型相比减少了约70%。
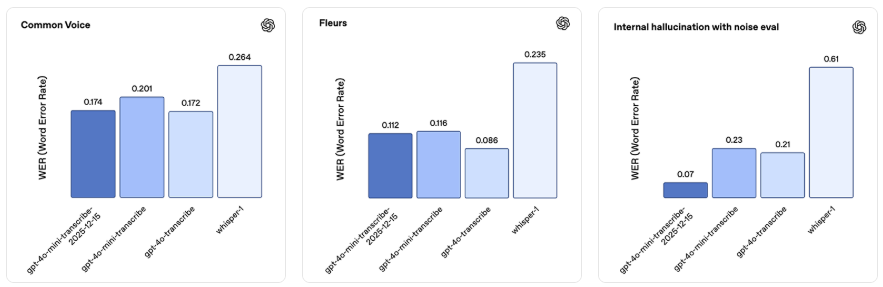
此模型快照在中文(普通话)、印地语、孟加拉语、日语、印尼语和意大利语方面表现尤为突出。
Custom Voices
自定义语音使企业能够以独特的品牌语音与客户沟通。无论你是在打造客户支持智能体还是品牌虚拟形象,OpenAI 的自定义语音技术都能让你轻松创建独特且逼真的语音。
这些新的语音转语音和文本转语音模型为自定义语音带来了改进,比如更自然的语调、对原始样本更高的还原度,以及跨方言准确性的提升
为确保安全使用这项技术,自定义语音仅面向符合条件的客户。如需了解更多信息,请联系您的客户经理或我们的销售团队。
从原型到投产
语音应用程序往往会在相同的方面出现问题,主要是在长对话中,或遇到如沉默等边缘情况时,以及在语音代理需要精准表现的工具驱动流程中。这些更新针对的就是这些容易出问题的情况,旨在降低错误率、减少幻觉(即生成不合理内容)、使工具使用更一致,并提高对指令的遵循程度。此外,还有一个额外的好处是,我们提升了输出音频的稳定性,让你的语音体验听起来更自然。
如果你目前正在发布语音相关产品,我们建议迁移到 2025 年 12 月 15 日的新快照版本,并重新运行关键的生产测试用例。早期测试者证实,无需更改指令,只需简单切换到新快照版本,就能看到明显的改进,但我们仍建议你针对自身用例进行测试,并根据需要调整提示词。
发表回复