
已经了解了大模型的基础概念、RAG、Agent、Transformer架构等核心知识。今天,我们将学习如何将预训练模型适配到自己的业务场景(微调),并将其稳定、高效地部署到生产环境(部署)。
微调让模型更懂你的业务,部署让模型真正服务于用户。两者结合,是AI应用落地的最后一公里。
一、为什么需要微调?
预训练大模型(如GPT-4、LLaMA)已经具备通用能力,但在特定场景下可能表现不佳:
● 风格不符:回答不够专业、语气不匹配。
● 知识缺失:不了解你的产品、公司内部术语。
● 结构要求:需要输出特定格式(JSON、表格)。
● 成本考量:频繁调用API成本高,微调小模型更划算。
1.1 微调 vs 提示工程 vs RAG
| 方法 | 适用场景 | 优点 | 缺点 |
| 提示工程 | 临时、简单任务 | 无需训练,即时生效 | 复杂任务不稳定,Token消耗大 |
| RAG | 知识问答、私有数据 | 实时更新,可解释 | 依赖检索质量,延迟稍高 |
| 微调 | 风格、格式、特定领域 | 深度定制,性能稳定 | 需要训练数据,成本较高 |
三者常结合使用:微调让模型“学会”你的领域知识,RAG提供实时信息,提示工程优化交互。
二、微调的核心流程
微调是在预训练模型的基础上,用少量任务相关数据继续训练,调整模型参数。
2.1 微调步骤
1. 数据准备:收集、清洗、格式化训练数据。
2. 选择基座模型:根据需求选择合适模型(如LLaMA、ChatGLM、Qwen)。
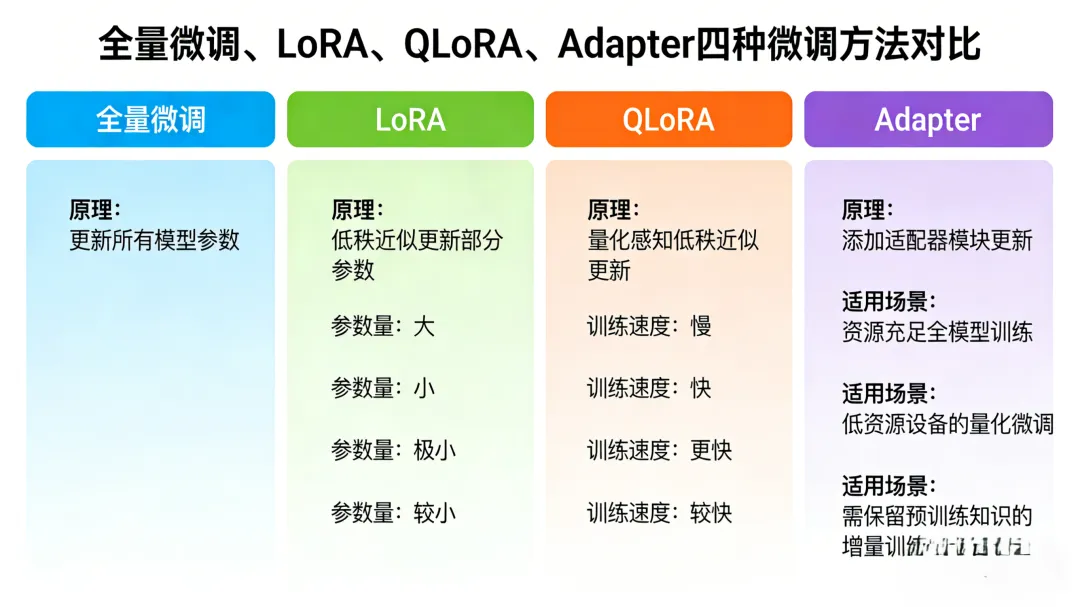
3. 微调方法:全量微调或参数高效微调(PEFT)。
4. 训练:设置超参数,启动训练。
5. 评估与迭代:用验证集评估效果,调整数据或参数。
6. 导出与部署:保存模型,量化优化,部署服务。
2.2 数据准备
● 数据格式:通常采用“指令-回答”对(instruction-input-output)或对话格式。
● 数量要求:几百条可看到初步效果,数千条以上效果更稳定。
● 质量优先:清洗数据,保证答案准确、风格一致。
示例数据(JSONL格式):
{"instruction": "解释什么是RESTful API", "output": "RESTful API是一种基于HTTP的架构风格,使用资源概念和标准HTTP方法(GET、POST、PUT、DELETE)进行通信。"}
{"instruction": "将以下英文翻译成中文:Hello world", "output": "你好世界"}2.3 微调方法
| 方法 | 说明 | 优点 | 缺点 |
| 全量微调 | 更新所有参数 | 效果最好 | 需要大量显存,训练慢 |
| LoRA | 低秩适配,只训练少量额外参数 | 显存占用小,训练快,易切换 | 效果略逊于全量 |
| QLoRA | LoRA + 量化 | 4-bit量化,单卡可微调几十B模型 | 精度略有损失 |
| Adapter | 插入小型网络层 | 参数少,易插拔 | 推理略增开销 |
目前LoRA/QLoRA是主流,尤其适合资源有限的环境。
三、微调实战:用LLaMA-Factory微调Qwen
LLaMA-Factory是一个易用的微调框架,支持多种模型和方法。以下示例使用Qwen-7B进行LoRA微调。
3.1 环境准备
git clone
https://github.com/hiyouga/LLaMA-Factory.git
cd LLaMA-Factory
pip install -r
requirements.txt
3.2 数据准备
将训练数据放在 data 目录,格式为JSON,并在 data/ dataset_info.json 中注册。
3.3 启动微调
python src/
train_bash.py
\
--stage sft \
--model_name_or_path Qwen/Qwen-7B \
--dataset my_dataset \
--template qwen \
--finetuning_type lora \
--lora_target q_proj,v_proj \
--output_dir ./output \
--per_device_train_batch_size 4 \
--gradient_accumulation_steps 4 \
--learning_rate 5e-5 \
--num_train_epochs 3 \
--fp163.4 合并权重并导出
训练完成后,将LoRA权重合并到基座模型,便于部署:
from peft import PeftModel
from transformers import AutoModelForCausalLM, AutoTokenizer
base_model =
AutoModelForCausalLM.from_pretrained("Qwen/Qwen-7B")
tokenizer =
AutoTokenizer.from_pretrained("Qwen/Qwen-7B")
model =
PeftModel.from_pretrained(base_model,
"./output")
merged_model =
model.merge_and_unload()
merged_model.save_pretrained("./merged_model")
tokenizer.save_pretrained("./merged_model")
四、模型部署:从训练到服务
部署的目标是将模型以API或服务的形式提供给其他系统调用。
4.1 部署方式对比
| 方式 | 适用场景 | 优点 | 缺点 |
| 模型API服务 | 通用,快速上线 | 简单,无需管理硬件 | 依赖第三方,成本可控性差 |
| 自托管(GPU) | 高频调用、数据敏感 | 完全控制,长期成本低 | 需运维GPU集群 |
| 边缘端 | 离线、低延迟 | 无网络依赖 | 模型需压缩,性能受限 |
| Serverless | 间歇调用 | 按需付费,免运维 | 冷启动延迟 |
4.2 常用部署工具
| 工具 | 特点 | 适用场景 |
| vLLM | 高吞吐、PagedAttention | 高并发生产环境 |
| TGI | Hugging Face出品,功能全 | 企业级部署 |
| FastAPI + Transformers | 简单灵活 | 原型、内部工具 |
| Ollama | 一键运行,本地友好 | 开发测试 |
| TensorRT-LLM | NVIDIA优化,极致性能 | 大规模生产 |
4.3 部署实战:使用vLLM部署微调后的模型
安装vLLM:
pip install vllm启动服务:
python -m
vllm.entrypoints.openai.api_server
\
--model ./merged_model \
--port 8000调用API:
import openai
openai.api_base
= "http://localhost:8000/v1"
openai.api_key
= "EMPTY"
response =
openai.ChatCompletion.create(
model="./merged_model",
messages=[{"role": "user", "content": "解释什么是微调"}]
)
print(
response.choices[0].message.content)
4.4 部署优化要点
● 量化:使用GPTQ、AWQ等量化技术,减少显存占用,提升推理速度。
● 批处理:动态批处理提高吞吐量。
● 缓存:对常见问题缓存结果,降低负载。
● 流式输出:提升用户体验,尤其对于长文本生成。
五、后端开发视角:集成微调模型
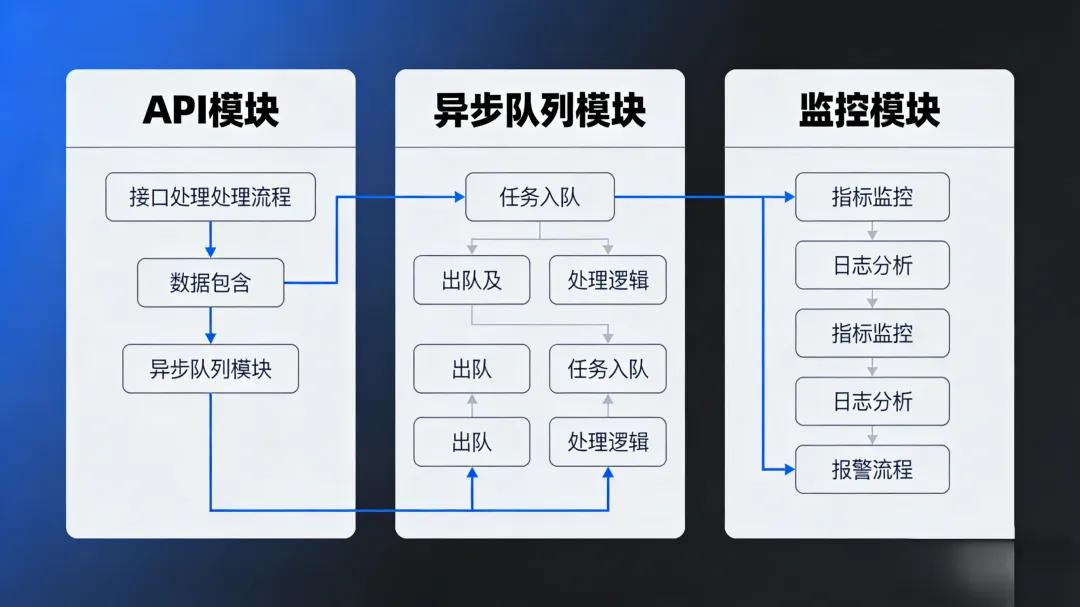
作为后端工程师,将微调模型集成到系统时需考虑:
● API设计:统一封装模型调用接口,便于前端和服务调用。
● 异步处理:耗时任务放入消息队列,避免阻塞。
● 监控与日志:记录请求、响应、耗时,用于质量分析和成本核算。
● 灰度发布:新模型先小流量验证,再全量切换。
● 版本管理:保存多个模型版本,支持回滚和A/B测试。
三、微调实战:用LLaMA-Factory微调Qwen
LLaMA-Factory是一个易用的微调框架,支持多种模型和方法。以下示例使用Qwen-7B进行LoRA微调。
3.1 环境准备
git clone
https://github.com/hiyouga/LLaMA-Factory.git
cd LLaMA-Factory
pip install -r
requirements.txt
3.2 数据准备
将训练数据放在 data 目录,格式为JSON,并在 data/ dataset_info.json 中注册。
3.3 启动微调
python src/
train_bash.py
\
--stage sft \
--model_name_or_path Qwen/Qwen-7B \
--dataset my_dataset \
--template qwen \
--finetuning_type lora \
--lora_target q_proj,v_proj \
--output_dir ./output \
--per_device_train_batch_size 4 \
--gradient_accumulation_steps 4 \
--learning_rate 5e-5 \
--num_train_epochs 3 \
--fp163.4 合并权重并导出
训练完成后,将LoRA权重合并到基座模型,便于部署:
from peft import PeftModel
from transformers import AutoModelForCausalLM, AutoTokenizer
base_model =
AutoModelForCausalLM.from_pretrained("Qwen/Qwen-7B")
tokenizer =
AutoTokenizer.from_pretrained("Qwen/Qwen-7B")
model =
PeftModel.from_pretrained(base_model,
"./output")
merged_model =
model.merge_and_unload()
merged_model.save_pretrained("./merged_model")
tokenizer.save_pretrained("./merged_model")
四、模型部署:从训练到服务
部署的目标是将模型以API或服务的形式提供给其他系统调用。
4.1 部署方式对比
| 方式 | 适用场景 | 优点 | 缺点 |
| 模型API服务 | 通用,快速上线 | 简单,无需管理硬件 | 依赖第三方,成本可控性差 |
| 自托管(GPU) | 高频调用、数据敏感 | 完全控制,长期成本低 | 需运维GPU集群 |
| 边缘端 | 离线、低延迟 | 无网络依赖 | 模型需压缩,性能受限 |
| Serverless | 间歇调用 | 按需付费,免运维 | 冷启动延迟 |
4.2 常用部署工具
| 工具 | 特点 | 适用场景 |
| vLLM | 高吞吐、PagedAttention | 高并发生产环境 |
| TGI | Hugging Face出品,功能全 | 企业级部署 |
| FastAPI + Transformers | 简单灵活 | 原型、内部工具 |
| Ollama | 一键运行,本地友好 | 开发测试 |
| TensorRT-LLM | NVIDIA优化,极致性能 | 大规模生产 |
4.3 部署实战:使用vLLM部署微调后的模型
安装vLLM:
pip install vllm启动服务:
python -m
vllm.entrypoints.openai.api_server
\
--model ./merged_model \
--port 8000调用API:
import openai
openai.api_base
= "http://localhost:8000/v1"
openai.api_key
= "EMPTY"
response =
openai.ChatCompletion.create(
model="./merged_model",
messages=[{"role": "user", "content": "解释什么是微调"}]
)
print(
response.choices[0].message.content)
4.4 部署优化要点
● 量化:使用GPTQ、AWQ等量化技术,减少显存占用,提升推理速度。
● 批处理:动态批处理提高吞吐量。
● 缓存:对常见问题缓存结果,降低负载。
● 流式输出:提升用户体验,尤其对于长文本生成。
五、后端开发视角:集成微调模型
作为后端工程师,将微调模型集成到系统时需考虑:
● API设计:统一封装模型调用接口,便于前端和服务调用。
● 异步处理:耗时任务放入消息队列,避免阻塞。
● 监控与日志:记录请求、响应、耗时,用于质量分析和成本核算。
● 灰度发布:新模型先小流量验证,再全量切换。
● 版本管理:保存多个模型版本,支持回滚和A/B测试。
六、总结与展望
核心要点
| 维度 | 关键内容 |
| 微调 | 用业务数据让模型更贴合场景,常用LoRA/QLoRA |
| 数据准备 | 指令-回答对,质量重于数量 |
| 部署工具 | vLLM(高吞吐)、TGI(企业级)、Ollama(本地) |
| 优化 | 量化、批处理、缓存、流式输出 |
| 后端集成 | API设计、异步、监控、灰度、版本管理 |
发表回复